このブログは、数年前にN高等学校を卒業し株式会社Armorisにやってきたアルバイト Kaepi が書いています。
あるもりすぶろぐの内容は個人の意見です。
概要
今回はフィッシングサイトの情報について、twitterで投稿をしている2つのアカウントからデータを取得し、IPや地域情報などの様々な要素の傾向を調べるために、elasticsearch+kibanaでデータの分析と可視化をしてみました。
また、今回は記事を3回に分けて投稿します。
1. フィッシングサイトの調査をしてみた - データ収集とパース編(この記事)
2. フィッシングサイトの調査をしてみた - elasticsearch+kibanaを使ってデータの可視化
3. フィッシングサイトの調査をしてみた - 可視化したデータの分析
情報元にさせていただいたアカウント
@secbird1
@pingineer_jp
今回の調査に必要なツイートの収集からelasticsearchへのデータ投入までを自動化するために、node.jsでプログラムを書きました。
目次
- 全体図
- twitterからツイートを収集する
- ツイート収集の自動化
- 収集したデータのパース
- まとめ
全体図
構成はこの様になっており、twitterから取得したツイートを一旦elasticsearchに投入してから、別のプログラムでデータの追加とパースを行います。

今回情報源にさせていただいたツイートを収集するために、Twitter API v2のSearch Tweetsという機能を使用しました。
ツイート収集の自動化
Twitter API v2で取得したツイートをelasticsearchに投入するところまでを自動化するために、node.jsでプログラムを書きました。
大まかな機能は
- Twitter API v2からツイートを取得する
- 送られてきたjsonをツイートごとに分割してelasticsearchに投入する。
となっており、これをnode-cronという指定した時間おき(今回は1時間に1回)に実行するライブラリを使って、自動でツイートを収集するようにしました。
const cron = require('node-cron')
const axiosBase = require('axios')
const twitter = axiosBase.create({
baseURL: 'https://api.twitter.com/2/tweets/search',
headers: {
'Content-type': 'application/json',
'Authorization': 'Bearer ' + bearar
}
})
const elastic = axiosBase.create({
headers: {
'Content-Type': 'application/json',
'X-Requested-With': 'XMLHttpRequest'
}
})
async function dump(account_name) {
let resCount = 0
const _date = new Date()
const date = `${_date.getFullYear()}-${_date.getMonth()+1}-${_date.getDate()}T${_date.getHours()-1}:00:00+09:00`
twitter.get('/recent', {
params: {
'query': `from:${account_name}`,
'start_time': date,
'tweet.fields': 'created_at',
'max_results': 100,
}
})
.then(res => {
for (let i of res.data.data) {
const data = { account_name: account_name, full_text: i.text, created_at: i.created_at}
postData(data, 'tweets')
resCount++
}
postData({state: 'log', log: `Dumped. \naccount: ${account_name}\ndata count: ${resCount}`, time: _date}, 'log')
})
.catch(err => {
const data = err.response.data
const message = `title: ${data.title}\ndetail: ${data.detail}\nerrors: ${data.errors[0].message}`
postData({state: 'error', log: message, time: _date}, 'log')
})
}
async function postData(data, index) {
elastic.post(`http:
.then(res => { console.log(res.data) })
.catch(err => { console.log(err.response.data) })
}
cron.schedule('0 * * * *', () => {
Promise.all(
[
dump('secbird1'),
dump('pingineer_jp')
]).catch(e => console.log(e.response.data))
})
※beararはAPIにアクセスするためのトークン
twitter API v2で取得したデータはこのようなjsonになっています。
[
{
created_at: '2021-11-30T03:33:05.000Z',
id: '1465524255723261953',
text: '三井住友カードのフィッシングサイトと思われます。だまされてはいけません。\n' +
'\n' +
'hxxp://wcermxoj.ml/\n' +
'( IP:Cloudflare Country:US Org:AS13335 Cloudflare, Inc. )\n' +
'\n' +
'#Phishing #フィッシング #三井住友カード #SMBC'
},
{
created_at: '2021-11-30T03:03:01.000Z',
id: '1465516691312758785',
text: '三井住友カードのフィッシングサイトと思われます。だまされてはいけません。\n' +
'\n' +
'hxxp://wcermxoj.tk/\n' +
'( IP:Cloudflare Country:US Org:AS13335 Cloudflare, Inc. )\n' +
'\n' +
'#Phishing #フィッシング #三井住友カード #SMBC'
},
...
]
収集したデータのパース
ツイートの内容のままだとelasticsearchで扱いにくいので、ツイートの内容を切り分けてそこから更に情報を追加していきます。
まずは上記のようなツイートから以下の要素に切り分けます。
- 名前を騙られたサービス名
- フィッシングサイトのURL
- IP
- 地域情報
- org(使用されているホスティングサービスの組織名)
さらに、geoipを用いてIPアドレスから大まかな座標を取得したり、ドメインに対してwhoisを行うなどして情報の追加を行いました。
外部コマンド(whoisやnslookupなど)を実行するときは、この関数から実行することでエラーが発生したかどうかを判別しています。
async function run(command) {
let res
try {
res = await exec(command)
} catch (e) { res = e }
if ( Error[Symbol.hasInstance](res)) return
return res.stdout
}
IPアドレスから座標を取得するためにgeoip-liteというnode.jsのライブラリを使用しています。
console.log(geoip.lookup('107.150.11.137'))
IPアドレスを引数にわたすだけで様々な情報を取得できます。
{
range: [ 1804992512, 1804996607 ],
country: 'US',
region: 'CA',
eu: '0',
timezone: 'America/Los_Angeles',
city: 'Los Angeles',
ll: [ 34.0549, -118.2578 ],
metro: 803,
area: 1000
}
ツイートを行ごとに分けてから、正規表現で要素の抽出と外部コマンドを実行をしています。
処理されたデータはPOSTでelasticsearchに送られます。
async function secbird(res) {
for (let i of res.body.hits.hits) {
i = i._source
let text = i.full_text.split('\n')
if (text.length > 5) {
text = text.filter(n => n !== '')
const name = text[0].match(/.+の/)[0].slice(0, -1)
const url = text[1].replace('hxxp', 'http')
const domain = url.replace(/http:\/\/|https:\/\/|/, '').replace('/', '').replace('/index', '')
let ip = await nslookup(domain) || text[2].match(/IP:[Cloudflare|\d\.]+/)[0].slice(3)
let whois = await run('whois '+domain) || "failed"
const country = text[2].match(/Country:\w+/)[0].slice(8)
const ll = await getll(ip)
if (ll === "") continue
const org = text[2].match(/Org:[-,.\s\w]+/)[0].trim().slice(4)
const data = { name: name, url: url, ip: ip, whois: whois, country: country, location: ll, org: org, created_at: i.created_at}
postData(data, 'secbird1')
}
}
}
elasticsearchに投入するパースされたjsonがこちらです。
{
"name": "PayPay銀行",
"url": "https://www.amazon.jp.nqg2.xyz",
"ip": "107.150.11.137",
"whois": "The queried object does not exist: DOMAIN NOT FOUND\n",
"country": "US",
"location": {
"lat": 34.0549,
"lon": -118.2578
},
"org": "AS8100 QuadraNet Enterprises LLC",
"created_at": "2021-11-11T00:45:51+00:00"
}
※このjsonに含まれるurlはフィッシングサイトのurlです。絶対にアクセスしないでください。
整形したデータはelasticsearchに投入してデータ収集とパースは終了です。
まとめ
今回はtwitterからツイートを収集して、データの追加とパース・elasticsearchに投入するところまでをnode.jsを使って自動化しました。
特にnode.jsから外部コマンド(nslookupやwhoisなど)を実行することが多く、コードを書いているwindowsのパソコンからではテストができなかったので大変でした。
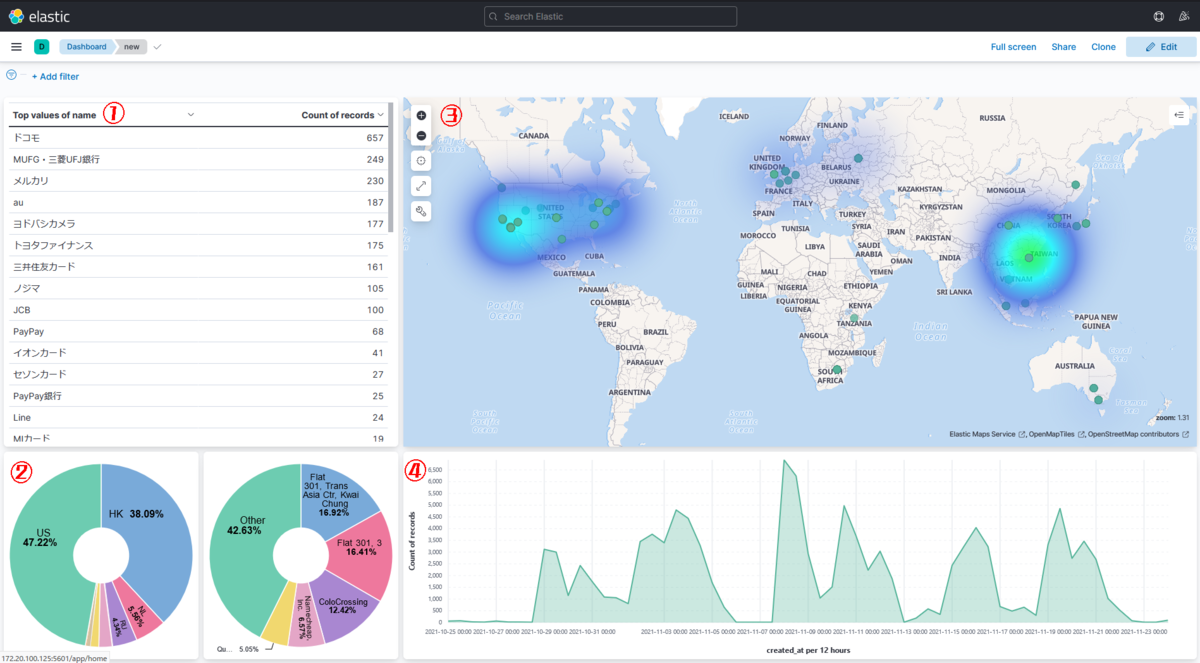
次の記事ではelasticsearchの構築と投入したデータの可視化について書くので、次回もよろしくお願いします。