このブログは、株式会社Armorisアルバイトのyanorei32がVRChatの沼底から書いています。 あるもりすぶろぐの内容は個人の意見です。
本稿では、beurtschipper/Depix を中心にDepixを紹介する。
概要を README.md から抜粋する。
Depix is a tool for recovering passwords from pixelized screenshots.
This implementation works on pixelized images that were created with a linear box filter. In this article I cover background information on pixelization and similar research.
具体的には以下のようなスクリーンショットからの文字列復元処理が行えるという主張である。

元となったとされているRecovering passwords from pixelized screenshots を読むと、どうやら非常に古典的な手法であることがわかる。
紹介記事に GPU や AI といった記述を見た為、 CNN的手法を予感したが、どうやら異なるようだ。 (ソースコードを見ても単純なfor文が書かれているだけだ。)
このソフトウェアの動作を知る為には、まず、モザイク処理に関して深く知る必要がある。
1. モザイク処理の基礎
モザイク処理は実際にはどの様な処理を行っているのだろうか。画像編集ソフトで以下の様なフィルター設定を見たことがあるかもしれない。
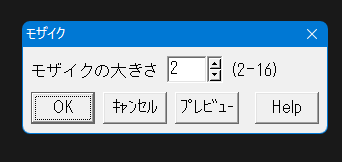
これは、非常に単純なフィルタで、近傍NxNピクセルの平均色を新しいピクセル色にするものである。(値として平均化する場合と、linear sRGB空間で行う場合などもある。各ソフトウェアにより実装が異なる場合がある。)
実際に処理すると以下の様になる。

動作は単純だが、適切なサイズでモザイク処理を行うと、処理結果から得られる情報は少なく非常に強力だ。右図から左図をヒントなしに推測することは困難だろう。
2. ヒントありのモザイク復元
ではヒントが有る場合はどうだろうか。例えば以下のような制約を課してみよう。
- フォント/レンダリングが既知
- 文字単位でのモザイク処理の連結である
- 16x16の文字が丁度4x4単位でモザイク処理されているなど
この場合だと偶然の重複がない限り、1:1対応で元の文字を復元することができる。
ではそれらの制約は現実に満たすことができるだろうか。
2-1. フォント/レンダリングが既知
この条件を満たすことは比較的容易だろう。
例えば、以下の様な画像を見たとき、人はxtermで有ることや、そのデフォルトフォント fixed で有ること、xtermの標準描画であることが推測できるだろう。
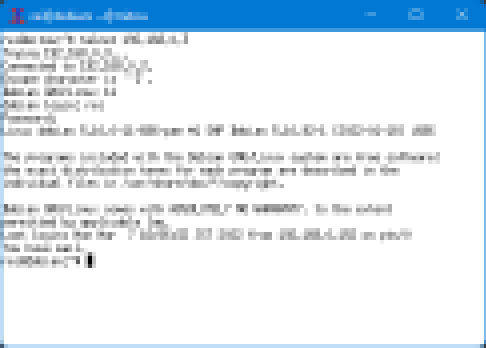
また、アプリケーションの他、OS標準フォントなどから推測することも可能であることから、比較的容易であると言える。
2-2. 文字位置が既知/モザイクと揃っている
制約「文字単位でのモザイク処理の連結である」を満たすのは困難であると言える。実際、Depixではこの制約なしに復元を試みている。
どの様に行っているのだろうか。
3. 連続文字列のリファレンス (Depix)
まず以下を仮定する。
事前に多くの連続文字のリファレンスを用意し、それに対するモザイク化を全通り行う。(サイズ5のピクセル化ならば25通り)
そこから、モザイク化された色情報から文字片への変換辞書を作る。
変換辞書を元に、辞書・入力データ間の距離を測りマッチング処理を行うアプローチがDepixの本質である。
3.1 beurtschipper/Depix の試用
以下に示すbeurtschipper/Depix 内の images/searchimages/debruinseq_notepad_Windows10_closeAndSpaced.png 等が辞書にあたる。

以下の様にスクリプトを実行し、サンプルの入出力を確認した。
git clone https://github.com/beurtschipper/Depix.git
cd Depix
python3 -m pip install -r requirements.txt
for f in images/testimages/testimage?_pixels.png; do
python3 depix.py \
-p $f \
-s images/searchimages/debruinseq_notepad_Windows10_closeAndSpaced.png \
-o $f.depix.png
done
3.1.1 testimage1_pixels.png

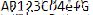
3.1.2 testimage2_pixels.png

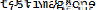
3.1.3 testimage3_pixels.png

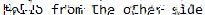
目で読むより明らかに良い精度での出力が得られていることがわかる。
しかし、よく見ると密度が近い別のグリフが参照されている箇所も多く見られる。
testimage1_pixels.png は、列が単純であるため推測可能だが、文脈が無いため誤読しやすい。
これは原理的な制約であると言えよう。
3.2 beurtschipper/Depixの実用
3.2.1 helloworld
次に、筆者環境 (Windows 11 21H2 旧メモ帳) で先程の辞書と同一のフォント (Consolas 11) にてレンダリングした Hello World という文字列を入力してみた。
original:

モザイク化 genpixed.py

出力 depix.py

残念ながら、何も得られなかった。
3.2.2 アンチエイリアスの無効化
ClearTypeによるアンチエイリアスにより、事態が複雑化している事を懸念しClearTypeが存在しない環境で施行してみようと考えた。
そこで、筆者のWindows XP (SP3)の環境にて、メモ帳に debruinseq.txt をレンダリングさせ、以下の画像を辞書に、その一行目を入力に、再試行した。
辞書:

入力と出力:

1 のハット部分や j のディティールはかなり復元できているのではなかろうか。
しかし、期待した品質ではなく、人間が直接目で読む精度とあまり変わらない。
3.2.3 様々な試行
xtermのレンダリング、異なるフォントサイズのレンダリング等、いくつかの条件を試したが、先の Hello World の例と同様に、殆どマッチングが取れなかった。
ここで、サンプルに付属する辞書を入力とし、それの復元を試みる方針を建てた。 これならば、レンダリング差異の問題は起こらず、また、当然、辞書とのマッチングも取りやすいはずである。
export F=images/searchimages/debruinseq_notepad_Windows10_closeAndSpaced.png python3 genpixed.py \ -i $F \ -o $F.pix.png python3 depix.py \ -p $F.pix.png \ -s $F \ -o $F.depix.png
得られた結果を以下に示す。最左列以外マッチングが取れていない。
beurtschipper/Depix f7d1850 現在、汎用性は無く、このレポジトリの成果物により直ちにモザイクが復元可能であるとは言えない様だ。

4. 考察
現状、復元は理想的な状況のみで行える様だが、「文脈/制約付きならば高精度に復元し得る」という主張は大変興味深い。
以下は筆者の所感である。
- 本実装のアイデアはそのままに、グリフ位置の制約をより強くする為、辞書/入力を1行にする事で精度向上し得るのではないか。
- 入力を自然言語に限定した上 (文脈的制約)、RNNの様な機械学習的アプローチを用いることで、より精度向上が期待できるのではないだろうか。
残念ながら筆者は、機械学習のリサーチャーで無いため、このアイデアを実装/実験する技術は持ち合わせていない。
beurtschipper/Depix は、筆者の様な初学者にも文脈/制約付き高精度デピクセライザーの登場を予感させる、非常に良い PoC であると言えよう。